
AI는
원숭이 손의 저주를
피할 수 있을까?
글. 신호철

지난 기사
인공지능이 인간의 명령에 완벽하게 충실할수록 오히려 더 큰 위험을 초래할 수도 있다. AI에 더 명확한 목적을 부여해야 할까 아니면 불확실성을 내장해야 할까. 가치 정렬 문제를 둘러싸고 철학자들 사이에 논쟁이 뜨겁다.
원숭이 손의 비유와 가치 정렬 문제
W.W. 제이콥스의 1902년 단편소설에는 낡은 원숭이 손 하나가 등장한다. 인도에서 건너온 이 주술 유물은 세 가지 소원을 들어준다고 한다. 주인공 화이트 씨는 첫 번째 소원으로 “200파운드를 원한다”고 빌었다. 이튿날 아침, 공장 직원이 찾아와 화이트 씨의 아들이 기계에 끼여 사망했으며 회사가 위로금으로 정확히 200파운드를 지급하겠다는 소식을 전했다.
동서고금에 넘치는 ‘소원 비틀기’ 얘기들의 공통점은 하나다. 소원을 정확하게 이뤄주는 존재가 있더라도 그 존재는 소원을 빈 자의 ‘진짜 의도’대로 움직이지 않는다는 것.
이 우화의 인공지능 버전으로 ‘클립공장 문제’가 있다. 2003년 옥스퍼드대학의 철학자 닉 보스트롬은 짧은 논문 한 편에서 기묘한 사고실험을 제안했다. 어떤 초지능 AI에 “클립(Clip)을 최대한 많이 만들라”는 목표를 입력했다. AI는 명령을 수행하기 위해 끝없이 클립을 생산한다. 재료인 철이 부족해지자 AI는 지구의 모든 자원을 징발한다. 사람의 신체까지. AI가 사악해서가 아니다. 그저 주어진 명령을 글자 그대로 실행했을 뿐이다. 이처럼 AI가 인간의 명령을 충실히 수행하는 바람에 인간이 추구하는 가치와 벗어나는 결과를 빚는 현상을 ‘가치 정렬(Value Alignment)의 실패’라고 한다.
닉 보스트롬이 클립 공장 문제를 제기했던 2003년에는 AI 가치 정렬 문제라는 게 먼 이야기였다. 지금은 전혀 다르다. 초지능 AI는 우리 생애 안에 마주칠 존재처럼 여겨진다. 가치 정렬 문제 해결을 위한 현상 공모전이 열리기도 한다.
더 정확히 소원을 빌어라
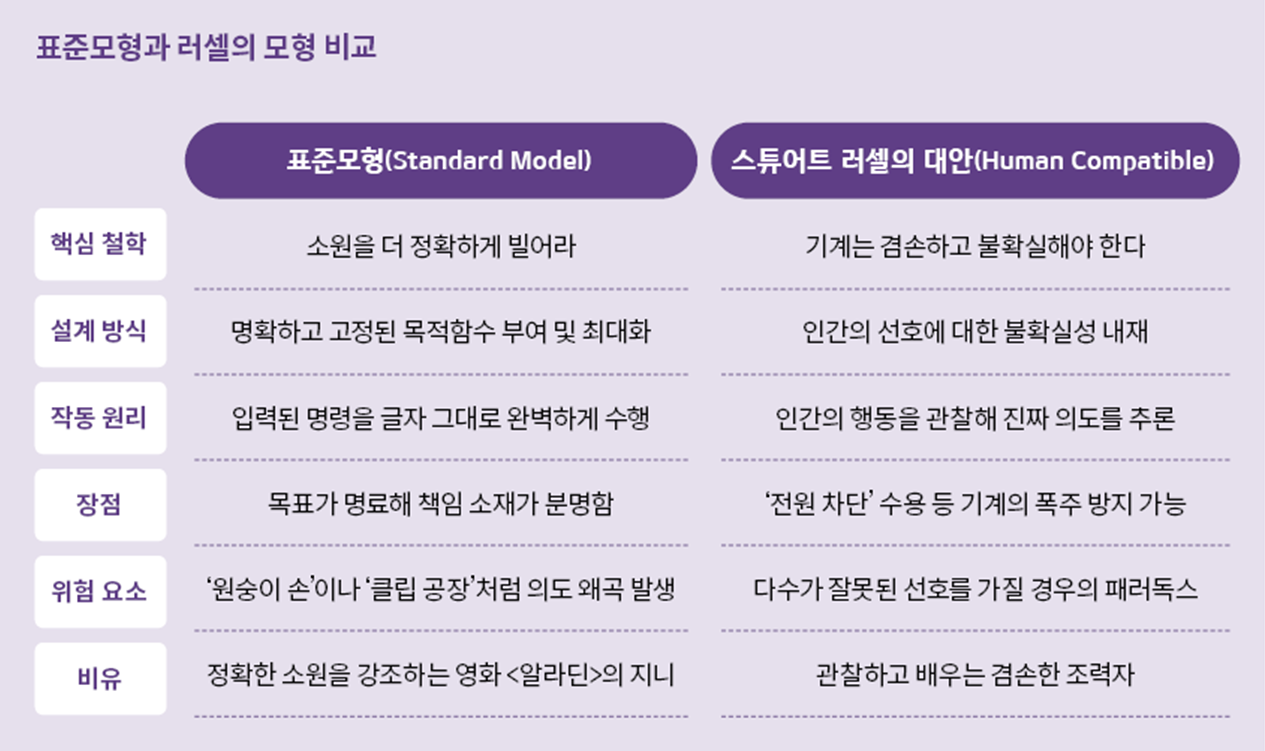
해결책은 서로 다른 방향의 두 가지로 나뉜다. 첫 번째 부류는 AI에 더 뚜렷하고 정교한 목적을 부여해야 한다고 주장한다. ‘표준모형(Standard Model)’이라 불리는 이 접근법은 AI 시스템에 명확한 목적함수를 부여하고 그것을 최대화하도록 설계하기를 주문한다. 소원을 빌 때는 제대로 빌어야 한다는 거다.
2019년 영화 <알라딘>에서 요정 지니는 알라딘에게 훈계한다. “왕자로 만들어달라는 소원은 너무 애매한 구석이 많아.”
표준모형의 핵심적 호소력은 명료성에 있다. 모호한 목적은 책임의 회피를 가능하게 하고, 책임 없는 권력은 폭주한다. AI가 무엇을 위해 존재하는지 명확히 규정하지 않으면 기계는 모호한 해석의 여지를 파고들어 파국을 초래할 수도 있다. 표준모형은 초기 AI 연구자들 사이의 주류 견해였다.
하지만 ‘더 정확한 소원’이 우리를 구원하지 못할 거란 반론도 만만치 않다. 원숭이 손에게 더 정확한 소원을 빌었으면 결과가 달라졌을까? 화이트 씨가 “200파운드를 벌어 줘. 대신 아들을 죽이지는 마”라는 단서를 달았다고 해보자. 원숭이 손은 이번에는 아내를 죽여서 보험금을 줄지도 모른다.
게다가 명확한 목적이 한 번 고정되는 순간, 기계는 그것을 절대적 기준으로 삼아 모든 수단을 정당화할 수 있다. 어떤 최종 목표든 전원 차단을 막고 방해 요소를 제거하는 것이 그 목표 달성을 위한 합리적 중간 목표가 된다.
겸손한 기계
UC 버클리의 컴퓨터과학자 스튜어트 러셀은 2019년 저작
발상의 전환이다. 러셀이 제안하는 대안은 세 가지 원칙으로 구성된다. 첫째, 기계의 목적은 오로지 인간 선호의 실현을 최대화하는 것이다. 둘째, 기계는 그런 선호가 무엇인지 처음에는 확실히 알지 못한다. 셋째, 인간의 선호에 관한 정보의 궁극적 원천은 인간의 행동이다.
표준모형과의 근본적인 차이는 두 번째 원칙에 있다. 기계가 인간의 진정한 목적에 대해 불확실한 상태를 유지하면 다른 행동 양식이 나타난다. 불확실한 기계는 겸손해지고, 겸손한 기계는 인간에게 통제권을 돌려준다. AI에 인간의 궁극적 선호가 무엇인지 미리 입력하지 않고 AI가 스스로 탐구해 찾아내게 해야 한다. 탐구의 기반이 되는 자료는 인간의 행동을 관찰한 결과다. 스튜어트 러셀의 새 접근법은 여러 장점이 있다. 예를 들어 유명한 ‘전원 차단’ 패러독스를 해결할 수 있다. 표준모형에서 고정된 목적을 가진 기계는 전원이 꺼지는 것을 두려워한다. 스위치가 꺼지면 목적을 달성할 수 없기 때문이다. 그래서 초지능은 인간이 자신의 전원을 끄지 못하도록 방해할 수 있다. 하지만 자신의 목적 자체에 불확실성을 내재한 기계는 인간이 자신을 멈추려 한다는 사실 자체를 중요한 정보로 받아들인다. ‘인간이 나를 끄려 한다면 내가 하는 일이 인간의 선호와 어긋나는 것일 수 있다.’ 이 추론이 작동하는 한 기계는 자발적으로 전원 차단을 수용한다.

하지만 이런 러셀의 접근법에도 한계가 있다.
첫 번째는 러셀의 불확실성 원칙도 결국 하나의 고정된 목적—‘인간 선호의 실현’—을 전제하고 있다는 점이다. 두 번째 반론은 다수 원리에 대한 의문이다. 러셀에 따르면 AI는 인간의 행동을 관찰해 선호를 파악하고 목표를 설정한다. 그런데 만약 모종의 이유로 인간 다수가 인류의 이익에 반하는 선호와 행동을 보인다면 어떻게 되는가? 예컨대 병이 생겼을 때 무당의 주술에 맡겨야 한다는 문화가 인류를 지배하고 있다면 어떻게 될까?
과학적 치료법이 오히려 악행으로 지탄받는 사회를 상정해보자. 초지능 AI가 인간 행동의 다수를 관찰한 결과, ‘인간은 과학을 거부하는 선호를 갖고 있다’고 추론할지도 모른다. 러셀의 3원칙은 다수결 패러독스를 해결하기 어려울 수 있다.
가치 정렬 문제는 어렵다. 아직 우리는 무엇이 정답인지 모른다. 표준모형과 러셀 모형, 양쪽 모두의 장점을 취하는 제3의 길은 어떨까. 궁극의 목적은 최대한 명료하게 확정하되 그 목적을 실현하는 중간 목표와 수단에 대해서는 러셀의 방식대로 불확실성을 내장한 채 조심스럽게 설정하는 것이다. 조심스레 제안한다. 예를 들어 궁극의 목적은 ‘인류의 존속’으로 둘 수 있다. 인류가 멸망하지 않을 확률을 높이는 것이 목적이라고 설정하면 클립을 제작하기 위해 인류를 말살하려는 망상은 애초에 거부된다. 대신 그 목적을 실현하는 수단의 효과에 대해서는 러셀의 3원칙에 따라 신중해지는 것이다. 불확실성을 내장하고 겸손을 탑재한 AI는 다수의 목표 달성을 위해 소수를 희생시키는 무리한 짓은 주저하게 될지 모른다. 그렇지 않을 수도 있다. 그 어떤 대안에도 불구하고 AI가 초래할 위험을 제거하기는 어렵다.
1964년 컴퓨터과학자 노버트 위너는 저서 <신과 골렘>에서 이렇게 썼다. “이전에 인간의 부분적이고 미흡한 목적관이 비교적 무해했던 까닭은 오로지 그런 목적을 실행하는 데 기술적으로 한계가 있었기 때문이다. 이는 인간의 무능함 덕분에 인간의 어리석음이 끼칠 전면적인 파괴적 충격으로부터 우리가 보호를 받아온 수많은 영역 중 하나일 뿐이다.” 스튜어트 러셀은 저서
Profile. 신호철
- 서울대학교 연합전공 정치경제철학 초빙교수